As part of the attack chain, the initial infection starts with attackers dispatching a malicious PDF as an iMessage attachment. This particular attachment is crafted to stealthily leverage a remote code execution vulnerability in the FontParser, identified as CVE-2023-41990 and reported by Valentin Pashkov, Mikhail Vinogradov, Georgy Kucherin (@kucher1n), Leonid Bezvershenko (@bzvr_), and Boris Larin (@oct0xor) of Kaspersky to Apple.
As someone who worked at the NSA, I always think it's hilarious when people feel like real APTs can be minimized to the MITRE matrix. https://t.co/BMywfpIS7K
— Ohm-I (Oh My) (@mcohmi) December 29, 2023
We learned in the blogpost published by Kaspersky few days ago that the exploit leverages the undocumented Apple-only ADJUST TrueType font instruction. We also learned that this instruction had been removed by a patch.
The whole exploit is a part of a sophisticated 0-click iMessage attack, utilizing four zero-day vulnerabilities, and is engineered to be effective on iOS versions up to and including iOS 16.2, operating without any visible indications to the user.
ADJUST TrueType font instruction 🔗
From the blogpost and few online references, we note that:
- This instruction has been removed, according to Kaspersky, so we can assume it is probably an obsolete instruction.
- There are two opcodes for this Apple-only instruction:
0x8fand0x90
This would mean that if we are able to scan a font for the presence of any of the above-mentioned single-byte signatures, we should be able to determine whether the font is malicious. However, it’s important to note that a regular YARA rule with a one-byte signature would likely result in false positives most of the time.
This means that we first need to understand where instructions are actually used within TrueType/OpenType fonts. After reviewing the documentation, we find pointers to three different locations:
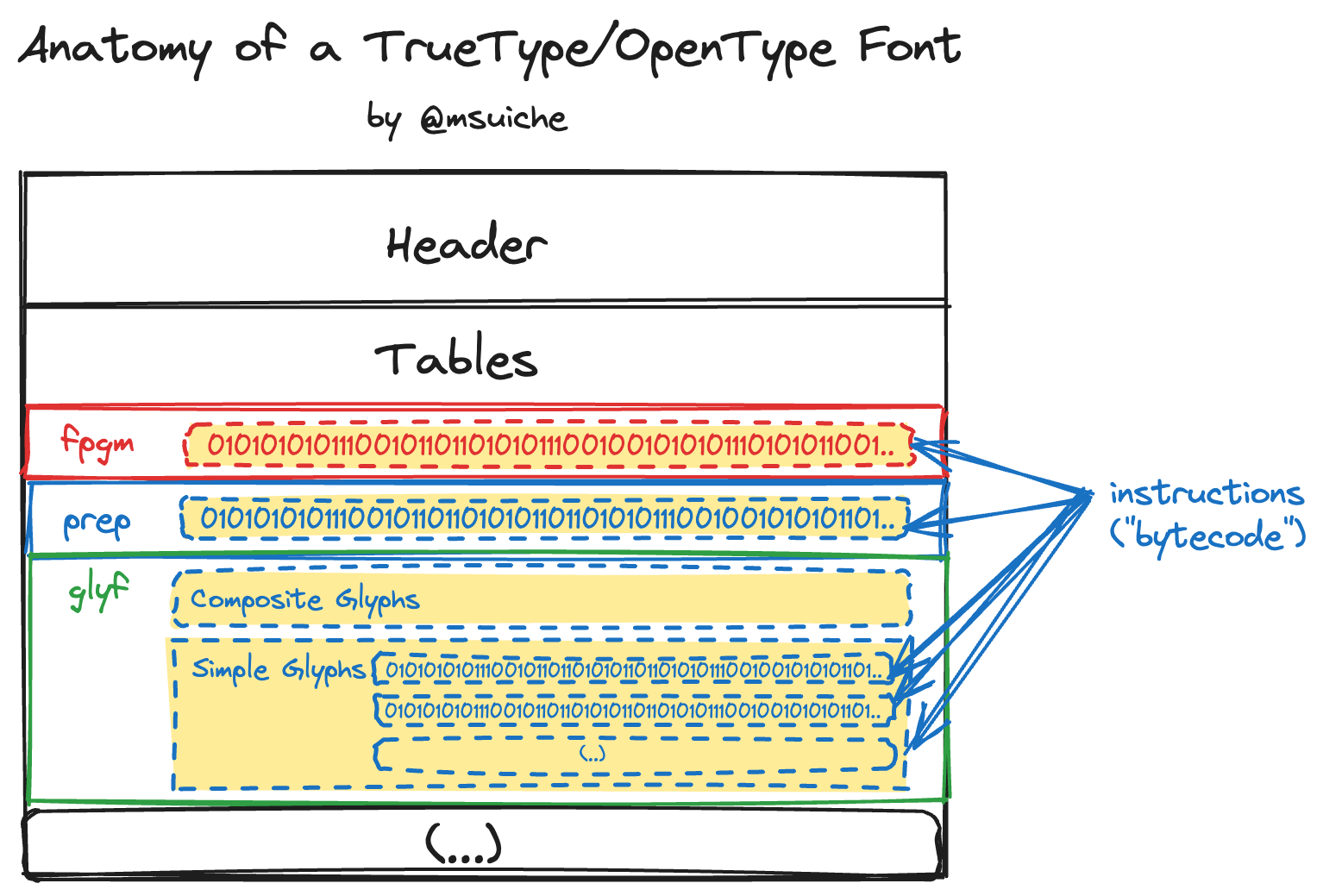
Font Program (fpgm) 🔗
The documentation tells us that this table is optional and used only once. Its format is very straight forward, as it only contains a series of instructions to be executed.
Control Value Program (prep) 🔗
Similar to the fpgm table, this table’s format is also straight forward and only contains a series of instructions.
The Control Value Program consists of a set of TrueType instructions that will be execute whenever the font or point size or transformation matrix change and before each glyph is interpreted.
Glyph Data (glyf) 🔗
The documentation tells us about two format of glyphes:
- simple
- and composite.
Each glyph description uses one of two formats:
Simple glyph descriptions specify a glyph outline directly using Bezier control points. Composite glyph descriptions specify a glyph outline indirectly by referencing one or more glyph IDs to use as components.
Glyphs, which were also referenced in the prep documentation, have a rich structure as they are used for drawing outlines. However, the “Simple Glyph” is particularly interesting because it can be instrumented. This is the reason why we are going to focus on them.
To filter out simple glyphs, we just need to ensure that the first value of the structure is equal to or greater than zero.
If the number of contours is greater than or equal to zero, this is a simple glyph. If negative, this is a composite glyph — the value -1 should be used for composite glyphs.
Simple Glyph 🔗
Simple Glyphes contain instructions, which are also referenced as “TrueType code” in some part of the documentation.
As we can see from the documentation, it presents a rich, assembly-like language that is probably worth exploring in more detail in a later blog post. For now, however, we will focus on the ADJUST instruction. According to some leaked source code available on GitHub, this instruction was introduced in 1991 initially to support Kanji characters, with added support by Microsoft in 1996 by Paul Linnerud. This spans over more than 30 years!
Disassembling TrueType code 🔗
To avoid false positives, we need to have basic support for TrueType opcodes, which are usually encoded in a single byte, with the exception of a few “instruction stream” opcodes, which are:
Once supported this gives us the ability to finally scan for the ADJUST (0x8f and 0x90) opcdes in the bytecode chunks we extracted.
See below the implementation in ELEGANTBOUNCER
fn is_adjust_inst_present(byte_data: &Vec<u8>) -> Result<bool> {
let mut off = 0;
while off < byte_data.len() {
let opcode = byte_data[off];
// https://securelist.com/operation-triangulation-the-last-hardware-mystery/111669/
// Undocumented, Apple-only ADJUST TrueType font instruction. This instruction had existed
// since the early nineties before a patch removed it.
if opcode == 0x8f || opcode == 0x90 {
debug!("0x{:x}: ADAPT /* Add Adjust Instruction for Kanji. Suspicious af. */", off);
info!("is_adjust_inst_present() returns to with values: offset {} with byte {:x}", off, byte_data[off]);
return Ok(true);
}
// NPUSHB[] PUSH N Bytes
else if opcode == 0x40 {
if off + 1 >= byte_data.len() {
return Err(ElegantError::TtfError(TtfError::OutOfRangeBytecode));
// return false;
}
let count = byte_data[off + 1] as usize;
off += 1;
if off + count >= byte_data.len() {
return Err(ElegantError::TtfError(TtfError::OutOfRangeBytecode));
}
debug!("0x{:x}: NPUSHB /* {} bytes pushed */", off, count);
off += count;
}
// NPUSHW[] PUSH N Words
if opcode == 0x41 {
if off + 1 >= byte_data.len() {
return Err(ElegantError::TtfError(TtfError::OutOfRangeBytecode));
}
let count = byte_data[off + 1] as usize;
off += 1;
if off + count * 2 >= byte_data.len() {
return Err(ElegantError::TtfError(TtfError::OutOfRangeBytecode));
}
debug!("0x{:x}: NPUSHW /* {} words pushed */", off, count);
off += count * 2;
}
// PUSHB[abc] PUSH Bytes
else if opcode >= 0xb0 && opcode <= 0xb7 {
let count = (opcode - 0xb0 + 1) as usize;
if off + count >= byte_data.len() {
return Err(ElegantError::TtfError(TtfError::OutOfRangeBytecode));
}
debug!("0x{:x}: PUSHB[{}] /* {} bytes pushed */", off, count, count);
off += count;
}
// PUSHW[abc] PUSH Words
else if opcode >= 0xb8 && opcode <= 0xbf {
let count = (opcode - 0xb8 + 1) as usize;
if off + (count * 2) >= byte_data.len() {
return Err(ElegantError::TtfError(TtfError::OutOfRangeBytecode));
}
debug!("0x{:x}: PUSHW[{}] /* {} words pushed */", off, count, count);
off += count * 2;
}
off += 1;
}
Ok(false)
}
Conclusion 🔗
There may be additional locations for scanning TrueType code that I’ve overlooked. I would be happy to incorporate support for these in ELEGANTBOUNCER.
Additionally, if anyone is able to test this tool on an Triangulation sample for validation purposes, their contribution would be immensely valuable. Your feedback and insights are not only welcome but also greatly appreciated in enhancing the effectiveness of this tool. ;)
I have to say, for a pet project that started with the aim of understanding zero-day vulnerabilities shared over iMessage, I’m surprised by how much can be achieved despite having no samples available, as nobody ever shares them.
That said, Happy New Year!